
Press Ctrl+ and K to search
请注意,本文编写于 2286 天前,最后修改于 1436 天前,其中某些信息可能已经过时。
目录
前言
最近一直在学爬虫,从最基本的urllib到requests、beautifulsoup到分布式爬虫框架scrapy,现在终于感觉可以上路了。所以先基于scrapy重写了我以前做的小说爬虫,代码都很简单,就不注释了。相关的知识点在我的python爬虫系列文章后面都会介绍到。
主要的参考文献:
思路
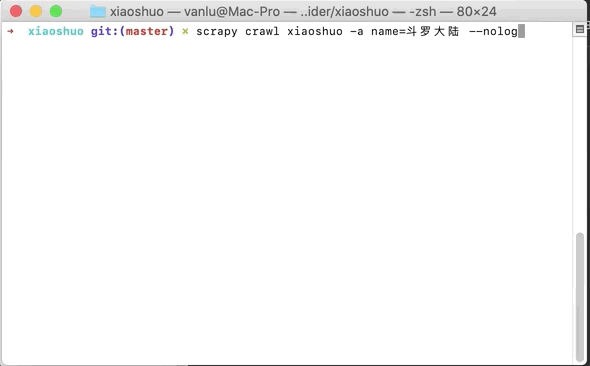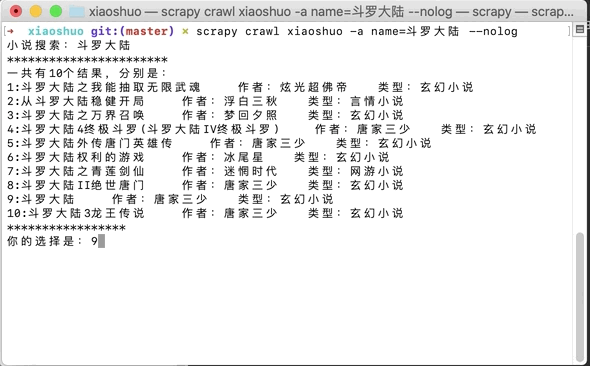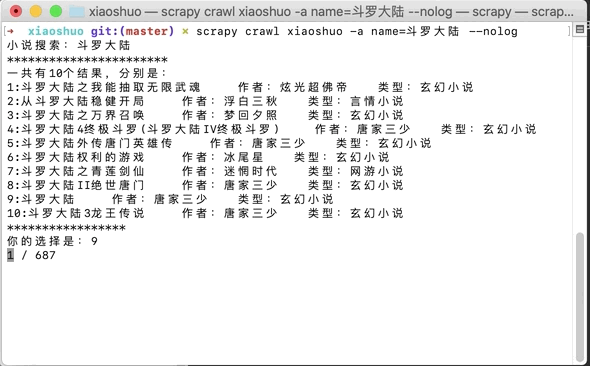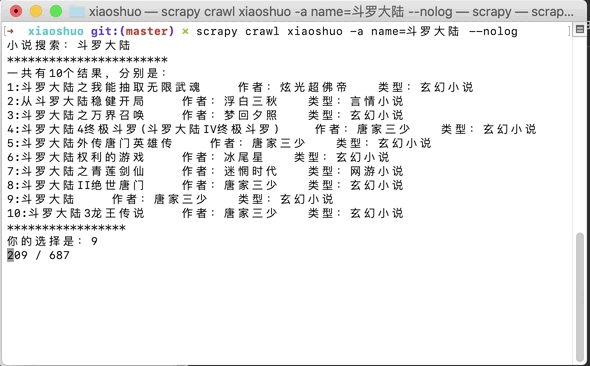
1.搜索小说名,用requests+lxml爬取结果,并让用户选择结果,返回小说目录的url
2.scrapy根据目录url解析小说章节数以及每章的具体url,其中把小说章节数送给item再到itempipeline保存,每章的url则是生成异步请求,结果送给parse_chapter进行下一步的解析
3.parse_chapter解析每一章的内容,替换没用的\xa0,写入到item里,返回交给pipeline处理
4.对于pipeline为了写入文件章节顺序是对的,每次返回的item都先保存到包括当前章节编号和内容的字典里
5.爬取完毕,对字典进行排序,写入到小说文件中
使用说明
依赖
需要安装:
scrapy requests
直接pip instal scrapy requests即可,如果scrapy安装不了需要编译没成功的话,那么到这个网站下载自己对应编译好的再用pip安装即可
运行
在项目目录中打开shell运行
shellscrapy crawl xiaoshuo -a name=小说名 --nolog
代码
如果对你有用的话,可以打赏哦
打赏


本文作者:mereith
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录